Last week, PostHog's CI ran 575,894 jobs, processed 1.18 billion log lines, and executed 33 million tests. At that volume, a 99.98% pass rate still produces thousands of failed runs that someone has to triage. We're building Mendral, an AI agent that diagnoses CI failures, quarantines flaky tests, and opens PRs with fixes. Here's what we've learned running it on one of the largest public monorepos we've seen.
PostHog's CI in one week
PostHog is a ~100 person fully remote team, all pushing constantly to a large public monorepo. They ship fast, and their CI infrastructure reflects that. Here's what one week looks like (Jan 27 - Feb 2):
- 575,894 CI jobs across 94,574 workflow runs
- 1.18 billion log lines (76.6 GiB)
- 33.4 million test executions across 22,477 unique tests
- 3.6 years of compute time in a single week
- 65 commits merged to main per day, 105 PRs tested per day
- 98 human contributors active in one week
- Every commit to main triggers an average of 221 parallel jobs
On their busiest day (a Tuesday), they burned through 300 days of compute in 24 hours. This is what a fast-moving team that takes testing seriously looks like.
The physics of scale
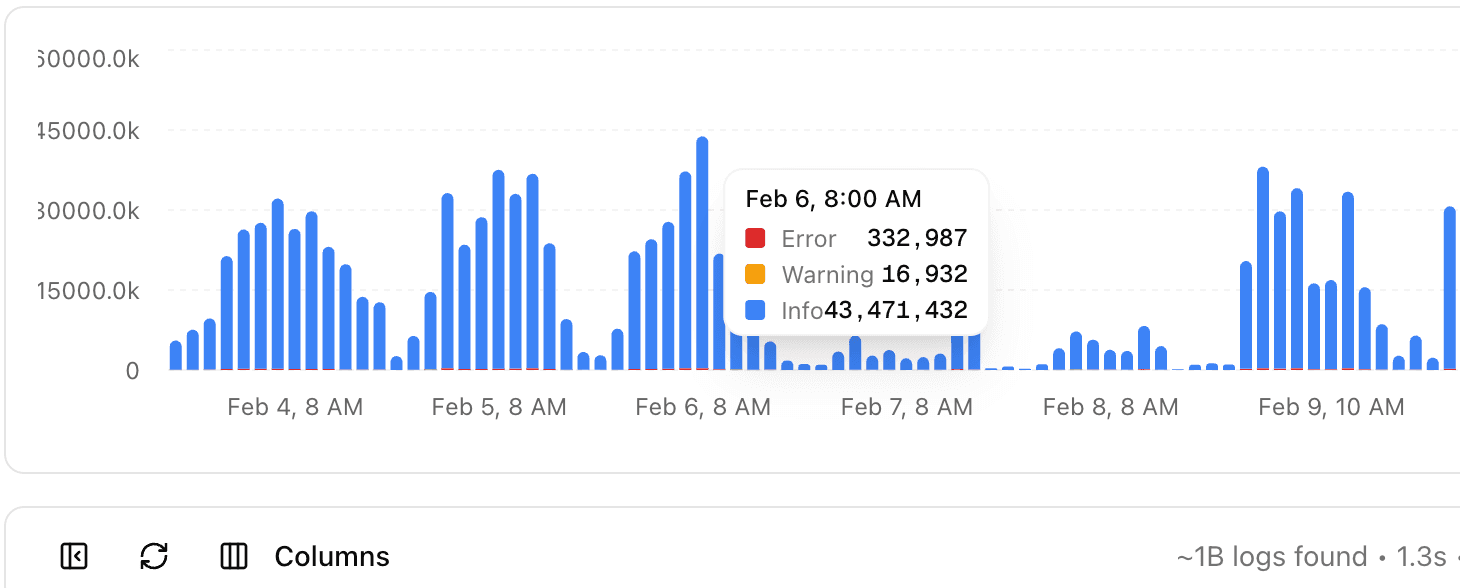
At this velocity, flaky tests become inevitable. PostHog's pass rate is 99.98% across 22,477 tests, which is excellent. But at 33 million weekly test executions, even a tiny failure rate produces thousands of failed runs. About 14% of their total compute goes to failures and cancellations, and roughly 3.5% of all jobs are re-runs.
This isn't a PostHog-specific problem. Any team operating at this pace with this test coverage will hit the same dynamics. The question is how you deal with it.
Most teams live with it. Engineers learn which tests are flaky, they re-run, they move on. It works up to a point. But when you have 98 active contributors and 221 parallel jobs per commit, the overhead of investigating and re-running adds up quietly. A test that passes 95% of the time fails multiple times a day at this volume. The individual failure isn't what hurts; the investigation does. Someone sees red CI, opens the logs, tries to figure out if their change broke something or if it's a known flake, re-runs, and pings someone on Slack. Three engineers might investigate the same flake independently. At 10 engineers, a flaky test is annoying. At 100, it's a tax on the whole team.
How Mendral works at PostHog
Mendral is a GitHub App. You install it on your repo (about 5 minutes), and it starts watching every commit, every CI run, every log output. Concretely:
Log ingestion at scale. We built a log ingestion system that processes PostHog's billion-plus weekly log lines so the agent can search and correlate failures fast. Without this, diagnosis is impossible. You need to pull the relevant logs from a failure and cross-reference with other recent failures to know if it's a flake or a real regression.
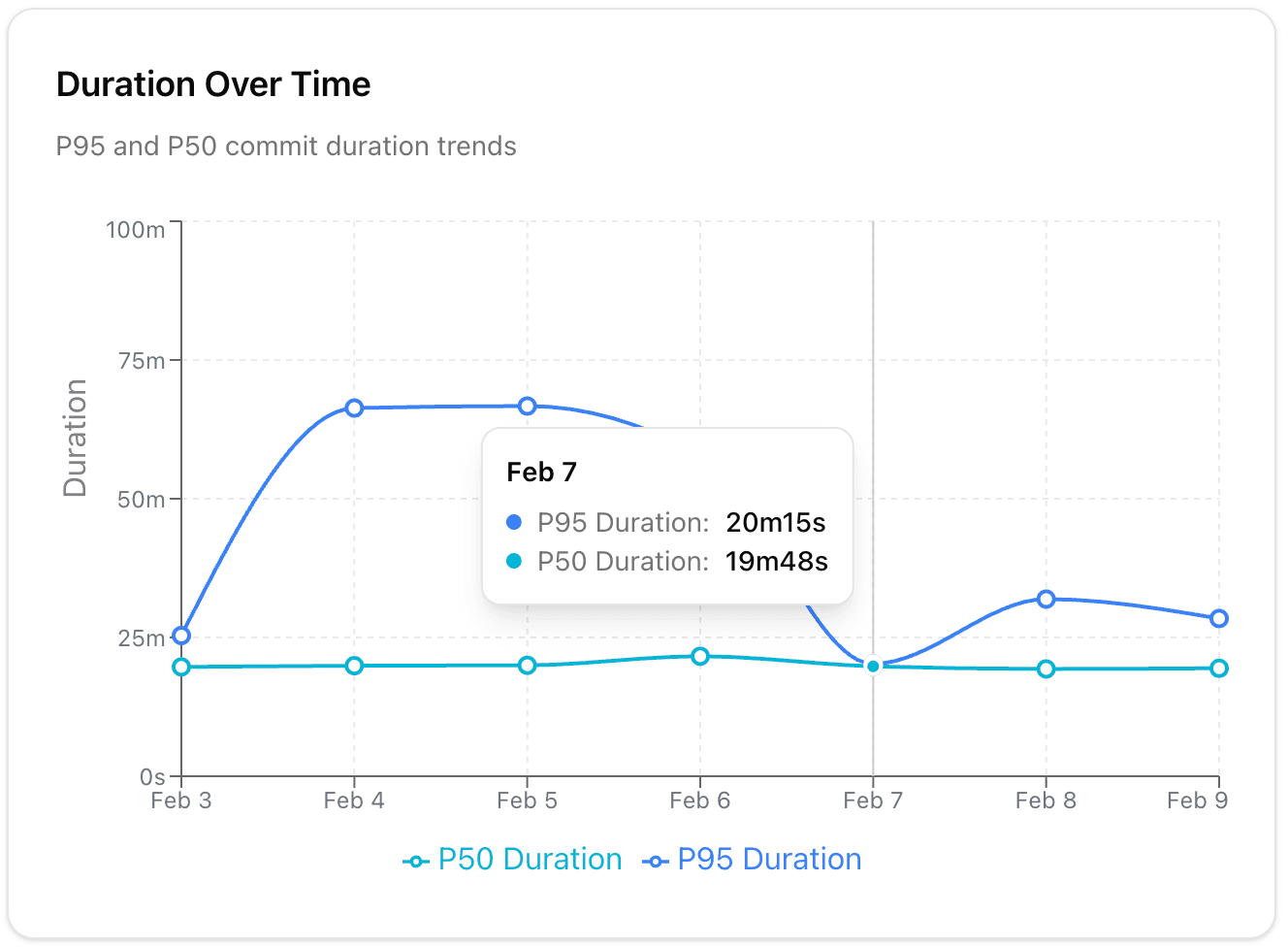
Tracing flakes to their root cause. The agent correlates errors with code changes. When it sees a test failing intermittently, it traces the flake to which commit introduced it and what infrastructure condition triggers it (sometimes it's infra slowness or side effects, not code). This is the part that takes a human the longest, and where the agent adds the most value.
Opening PRs. When the agent has enough confidence in a diagnosis, it opens a pull request to quarantine or fix the test. PostHog's repo is public, so these PRs are visible to anyone. You can go look at them right now. The agent iterates on the PR based on review comments, just like a human would.
Acting as a team member on Slack. The agent joins Slack and behaves like a team member. It doesn't broadcast failures to a general channel. Every member of the PostHog team linked their account to the Mendral dashboard, so the agent knows who to involve. If your commit likely caused the failure, you get a direct message. If it's a known flake, the agent handles it without interrupting anyone. The PostHog team pushed us to build this more carefully than we originally planned, and it's become one of the highest-leverage features.
Four things that surprised us
Log ingestion is the hard problem. Everyone focuses on the AI/diagnosis part, but the real bottleneck is getting billions of log lines indexed and searchable fast enough to be useful in real time. If your agent can't search logs in seconds, it can't diagnose anything before the engineer has already context-switched to investigate manually.
Flaky tests are rarely random. Almost every "flaky" test has a deterministic root cause, just one that's hard to find: timing dependencies, shared state between tests, infrastructure variance, order-dependent execution. The agent is good at this because it can correlate across hundreds of CI runs simultaneously, something a human wouldn't have the patience to do.
Routing matters as much as diagnosis. Knowing who to notify about a failure is almost as valuable as knowing what failed. At PostHog's scale, a failure notification in a general channel means 98 people glance at it and 97 ignore it. Having the agent figure out who actually needs to look at it, based on the code change and the failure signature, removes a lot of noise.
Working on a public repo keeps us honest. Every PR our agent opens on PostHog's repo is visible. Anyone can see how the agent reasons about failures and what fixes it proposes. That forces a level of transparency we couldn't have engineered ourselves.
What this looks like in two years
The volume problem will keep getting worse. AI coding tools are increasing the rate of code changes, which means more CI runs, more failures, more flakes to diagnose. PostHog gave us a preview of what a lot of fast-moving teams will look like in a couple of years: 22,477 tests, 65 commits to main daily, 98 engineers productive on a single monorepo. We got lucky onboarding them early in our YC batch. Their scale forced us to solve real problems at real volume from day one, in ways we couldn't have simulated.
We're Sam and Andrea. We scaled Docker's CI starting in 2013, back when 100-person teams running open-source CI was a new problem. If your team is paying the flaky-test tax PostHog was paying, we'd love to look at your numbers.