Mendral runs thousands of agent sessions a day across our customers. Some are the work we built it for: reviewing code, fixing CI, triaging incidents. Others are automations our customers built themselves: recurring engineering chores, specific to one team, that nobody wants to do by hand.
Blaxel runs seven of them in production without having written a single one; they described each in Slack and an agent built it.
The work every team has, and the work only you have
Mendral ships with agents for the DevOps work every team has. It reviews code against your test history and your past incidents. It reads dependency changes for supply chain attacks. It keeps CI green and fast, and it triages incidents when prod breaks. We ship that on by default because every engineering team needs it, and none of it is what makes your product yours.
But every team also has work that's specific to them. Enforce that every PR links a tracking issue. Check that new features ship with observability. Post a changelog every Monday so the team knows what went out. No vendor ships these, because they're yours.
Before AI, that work had two homes. You hired platform engineers to build and run it, or you pulled product engineers off the product to do it by hand. Most teams can't justify the first and quietly resent the second, so the chores get done late, done badly, or not at all.
Automations are the third option.
Why we built them
Automations work because of what Mendral already is. It's a multi-agent system, and the agents share one memory and one set of connections into your stack: your CI, your code, your issue tracker, your observability and infra services. That access is why Mendral can review a diff against your incident history or open a fix PR when a build breaks. It's also why an automation can act on what it finds: open a PR, file an issue, comment on the diff, with the same connections the core agents use.
The access is the hard part. Once an agent can read your CI logs, see your past incidents, and write to your repo, pointing it at the work that's specific to your team is the easy part. That's also the work we couldn't ship as a feature, because it looks different at every company. So you describe it, and the agent builds it.
There's a second reason. A lot of the boring work is also what gives a team confidence to ship. A testing guide on every PR, observability on every new feature, a tracking issue that never gets skipped: these are the checks that let people merge without second-guessing, and they're the first to slip when everyone's busy. An agent holds them so they happen every time, which raises the bar on what reaches prod.
An automation is a small agent
An automation has four parts: a trigger, a prompt, a set of integrations, and the tools it's allowed to use.
The trigger is a cron schedule or a GitHub event like a PR opening or a push, with CI and Slack triggers on the way. The prompt is instructions, written the way you'd brief a teammate: "You are a daily Sentry triage agent. Surface unresolved errors that need attention today." Integrations are the services it can reach, like Slack, Sentry, and Linear. Every automation also gets the same built-in tools our always-on agents use: your filesystem, insights, web search, memory, and CI logs. Writing to GitHub (opening PRs, commenting, re-running CI, pushing branches) is off by default and sits behind an explicit permission.

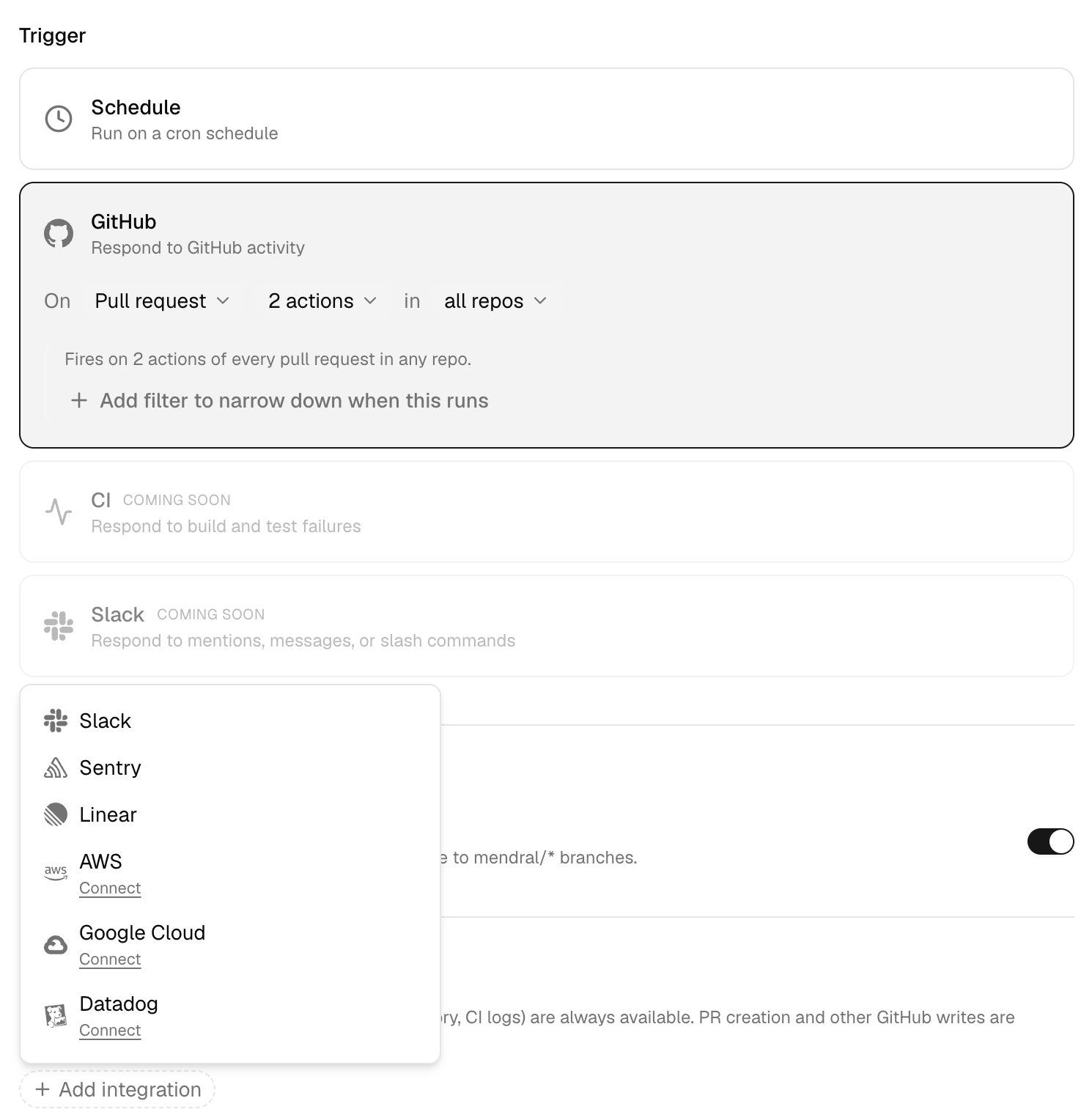
Each automation runs as a scoped agent on the same harness as the rest of Mendral. It reasons at runtime against your real repo, your CI logs, and your history. It shares the same memory too, so what Mendral learns triaging your incidents sharpens the automation that files them.
There's a name forming for this shape. Steinberger's version: stop prompting coding agents, start designing the loops that prompt them. Boris Cherny, who runs Claude Code, says he doesn't prompt Claude anymore; loops do it for him. An automation is that loop. The trigger decides when the agent gets prompted, the prompt carries the intent, and the permissions bound what it can touch. The part nobody mentions is who designs the loop.
You don't design the loop. You describe it.
Blaxel didn't fill out that config form seven times.
For each job, someone described it to Mendral in Slack. "File our open insights into Linear as triage issues." "Make sure every PR has a Linear issue, and create one if it doesn't." Mendral wrote the prompt, picked the trigger, wired up Linear and Slack, and posted the whole thing back to approve. When it wasn't quite right, they edited it in the same chat until it was, then promoted it to a schedule or a PR trigger.
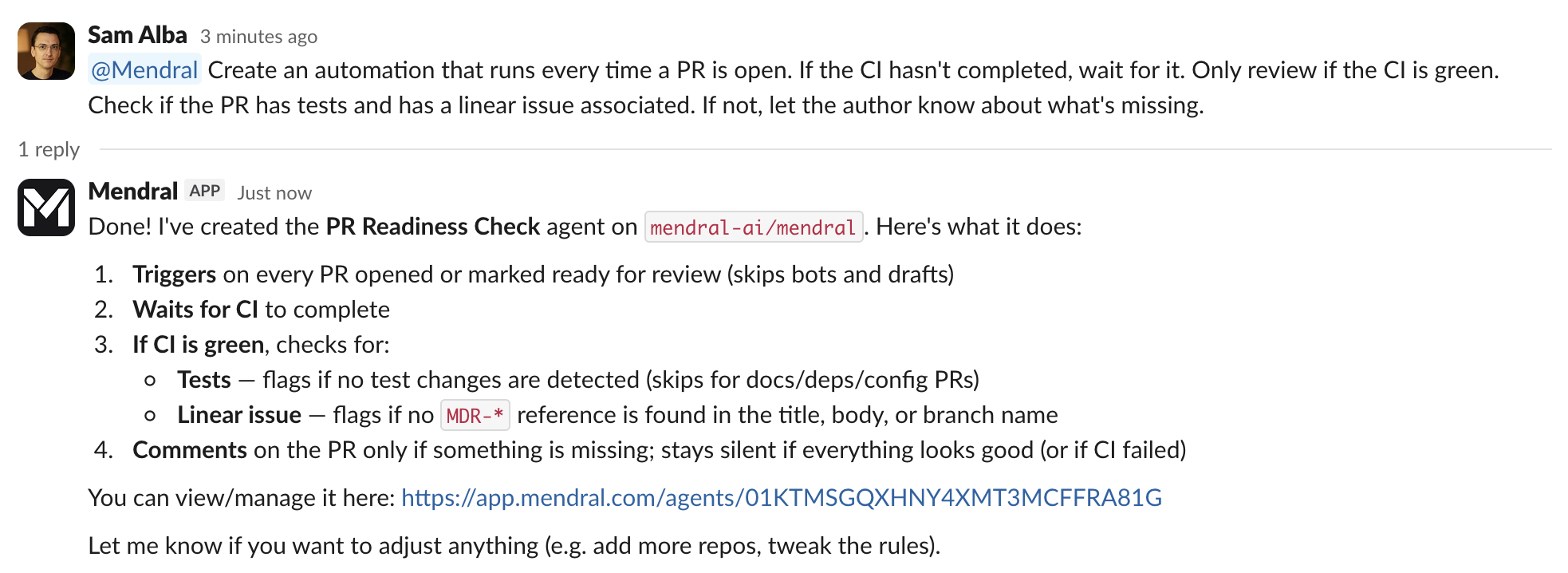
The engineer who wants the automation is the one who gets it. No platform-team ticket, no YAML to learn, no waiting a sprint. You describe the boring thing you keep doing, and the agent that already knows your stack builds it.
Seven automations, and any team can build them
Here's what Blaxel runs. None of it is special access. Every one of these uses capabilities any Mendral customer already has.
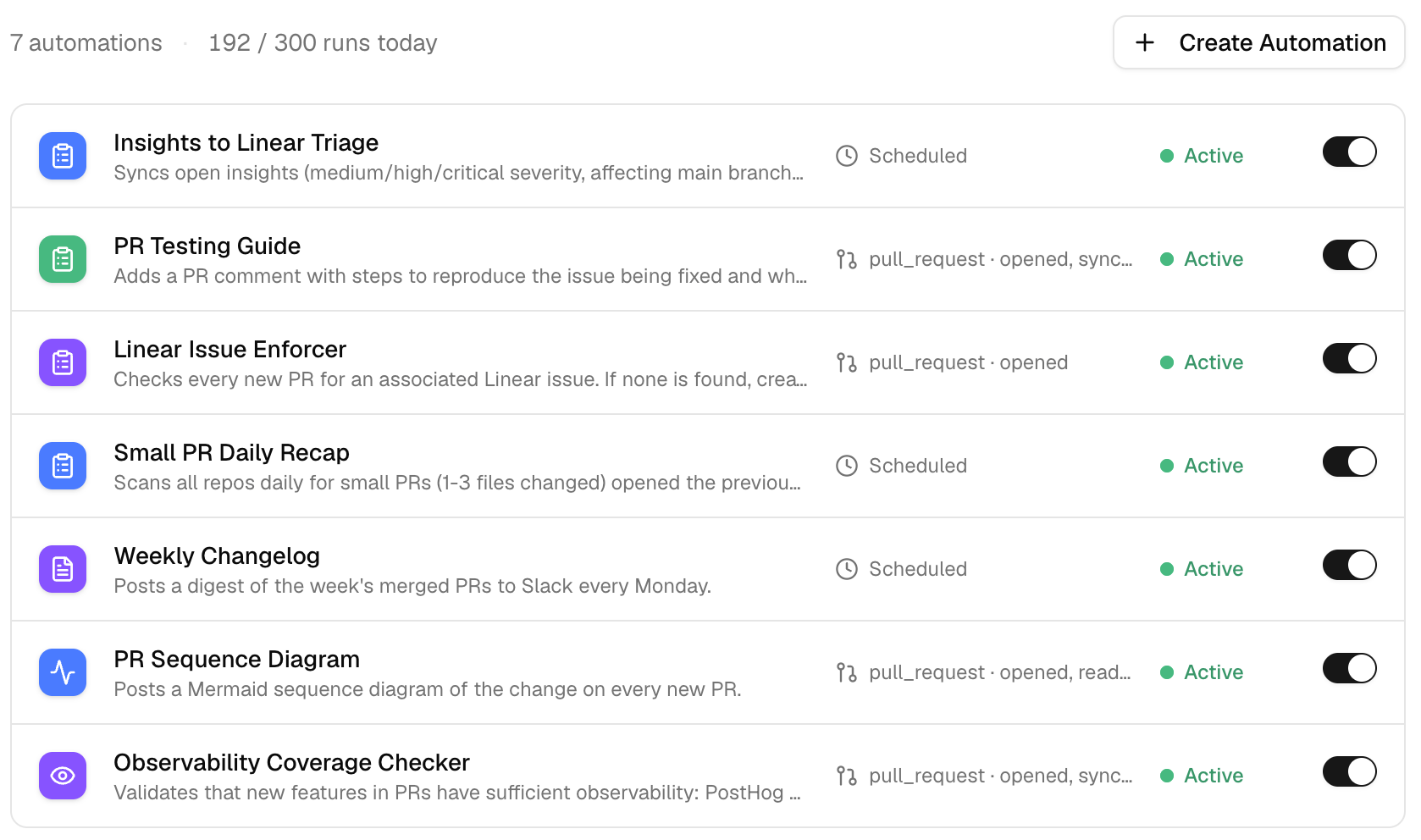
Two keep their tracking honest. One files open Mendral insights into Linear as triage issues, but only the ones worth a human's time: medium severity and up, on the main branch, deduplicated against what's already filed. Another checks every new PR for a linked Linear issue and creates one when it's missing. When the PR author is a coding agent instead of a person, it doesn't assign the issue to the bot. It reads the requested reviewers and assigns the human who's actually on the hook.
Three clean up pull requests. One posts a testing guide on each PR: what the change does, how to reproduce the original bug, what to verify. One checks that new feature code ships with observability, the analytics events, traces, and error tracking the team's own conventions require, and says exactly what's missing when it doesn't. A third posts a Mermaid sequence diagram of the change, so a reviewer sees the flow before reading the diff.
Two keep the team informed. One scans every repo each morning for small PRs opened the day before, the one-to-three-file changes that are quick to review, and posts them to Slack with the right human tagged. The last drafts a Monday changelog from the week's merged PRs, grouped into features, fixes, and infra, written in plain English instead of pasted commit titles.
None of these is hard. All of them are the kind of work that slips when people are busy, which is most weeks.
Why this isn't Zapier or a GitHub Action
There are plenty of ways to automate a workflow. Zapier, n8n, Make, and the newer agent builders give you an engine that knows nothing about your codebase, your CI logs, or last quarter's incident. GitHub Actions gives you deterministic YAML that you write once and maintain forever. The agentic-DevOps platforms bolt an agent onto their own pipeline product.
Two things are different here. The automation is authored by an agent that already has your repos, your CI history, your past PRs, and your team's memory. And each automation reasons at runtime, the way our always-on agents do. If you think in Kubernetes terms, each automation is a control loop: desired state in the prompt, a trigger that watches, an agent that reconciles. The difference from a controller is that the reconcile step can read.
The Linear enforcer is the clearest example. Deciding who to assign when the PR author is a bot isn't a rule you can write once. You'd have to code every branch: check the reviewers, fall back to the code owner, fall back to recent committers. The agent reads the PR and works it out, the way a person would. Multiply that across seven automations and you're describing intent, not maintaining logic.
What's still hard
Agents don't produce byte-identical output every run. For triage, review, and summaries, that's fine, and often better than a rigid template. For anything that has to be exact, you still want a deterministic check, and we'll say so.
Runs cost money and compute. Pointing an agent at every PR across every repo adds up, so part of setting this up is being honest about which work deserves an agent and which is a five-line script. Not everything should be an automation.
Writes are the part to respect. An agent that can open PRs, push branches, and re-run CI is exactly as powerful as that sounds, which is why GitHub writes stay off until you turn them on, per automation. A human approves every automation before it runs and can edit the prompt any time after. We think that's the right amount of friction.
The DevOps work every team has, Mendral already does. The work only your team has, you can now hand to an agent by describing it in a sentence. That used to mean hiring a platform engineer or taking a product engineer off the product for a week. Now it's a Slack message, and the team stays on the thing they're actually building.